오픈소스 AI 모델과 데이터셋 사례 : StarCoder와 The Stack - 이철남 교수(충남대학교)
오픈소스 AI를 둘러싼 논의
생성형 AI는 빠르게 발전하고 있지만, 동시에 베일에 싸여 있다. 마치 블랙박스처럼, AI가 어떻게 작동하고 어떤 데이터를 기반으로 판단하는지 알기 어렵다. 이러한 불투명성은 AI 기술에 대한 불신과 오해를 낳고, 잠재적인 위험을 가중시킬 수 있다. 전통적인 오픈소스 소프트웨어는 이러한 문제에 대한 해결책을 제시할 수 있으며, 오픈소스 커뮤니티의 입장에서 바람직한 AI 모델은 어떠해야 하는가에 대한 논의가 활발하다. 가장 대표적인 사례가 오픈소스 AI에 관한 정의(The Open Source AI Definition, 이하 ‘OSAID’)를 둘러싼 논의이다. 이 논의를 주도한 오픈소스 이니셔티브(Open Source Initiative)는 최근 OSAID 1.0을 발표했다.[1] 이 정의는 전통적인 오픈소스 소프트웨어의 원칙을 AI 시스템에 적용하여 투명성과 접근성을 보장하고, AI 기술의 민주화를 촉진하는 것을 목표로 한다. OSAID는 AI 시스템이 오픈소스로 간주되기 위해 충족해야 할 4가지 핵심 자유를 명시하며, 이를 위해 AI 시스템의 다양한 구성 요소에 대해 구체적인 투명성 요구 사항을 제시한다. OSAID는 특히 데이터 정보(Data Information)의 투명성과 관련하여, 학습데이터에 대한 충분한 세부 정보(예: 출처, 선택 기준, 라벨링 및 처리 방법)가 제공되어야 하며, 데이터 자체를 반드시 공개할 필요는 없지만, 동일한 수준의 성능을 가진 모델을 재현할 수 있을 정도로 상세해야 한다고 규정한다. 특히 (1) (공유 불가능한 데이터를 포함하여) 학습에 사용된 모든 데이터에 대한 완전한 설명, 데이터 출처, 범위 및 특성, 데이터 획득 및 선택 방법, 레이블링 절차, 데이터 처리 및 필터링 방법 공개; (2) 공개적으로 사용가능한 모든 학습데이터 목록 및 출처; (3) (유료를 포함하여) 제3자로부터 얻을 수 있는 모든 학습데이터 목록 및 출처가 포함되어야 한다고 규정한다.[2]
StarCoder
2024년 5월 발표된 기초 모델[3] 투명성 평가지표(The Foundation Model Transparency Index , 이하 ‘FMTI’)[4]에서는 14개 모델들 중에서 StarCoder가 가장 좋은 평가를 받았으며, GPT-4, Gemini, Claude3 등 현재 상업적으로 많이 활용되고 있는 모델들은 각각 11위, 12위, 10위로 상대적으로 낮은 평가를 받았다.[5]
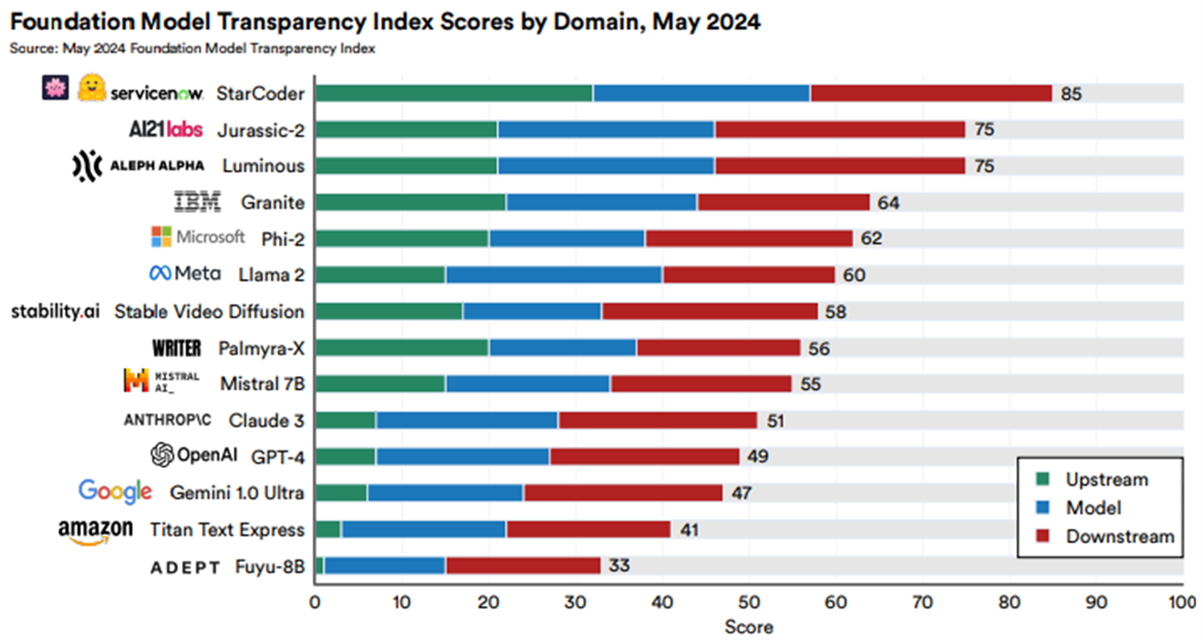
FMTI는 상류 자원(Upstream Resources), 모델 자체(Model Information), 하류 활용(Downstream Use)에 관한 100개의 세부 지표(indicators)를 기반으로 기초 모델의 투명성을 평가한다. 평가 지표 중 데이터와 관련된 평가 항목은 상류 자원 영역에 포함되며, 이는 기초 모델 개발에 사용된 데이터의 투명성을 평가하는 데 초점을 맞춘다. 이 영역은 모델의 학습에 필요한 데이터의 출처, 처리 방식, 그리고 데이터와 관련된 윤리적 고려사항을 다룬다. 예를 들면, 데이터 출처와 관련하여 학습에 사용된 데이터셋의 출처가 명확히 공개되었는지, 사용된 데이터의 저작권 보호 여부와 관련 라이선스가 공개되었는지 여부 등이 평가 항목으로 포함되어 있다.[6]
데이터 항목과 관련해서도 가장 높은 점수를 받은 AI 모델은 StarCoder이다. 모든 학습데이터가 GitHub 공개 리포지토리로부터 수집되었으며, 리포지토리 리스트와 작성자를 확인할 수 있다는 점, 또한 각 리포지토리의 라이선스를 확인할 수 있으며, MPL, EPL, LGPL 등 카피레프트 라이선스는 제외되었고, opt-out 요청된 코드도 제외되었다는 점에서 높은 평가를 받았다.[7] 반면, GPT-4, Gemini, Claude3는 데이터 관련 정보가 전혀 없거나 극히 일부만 공개되어 있을 뿐이다.
The Stack
StarCoder는 BigCode 프로젝트[8]를 통해 개발되었는데, 이 프로젝트에서는 "The Stack"이라는 대규모 오픈소스 코드 데이터셋을 사용하여 모델을 학습했다. 이 데이터셋은 Software Heritage[9], GitHub 등에서 수집된 오픈소스 리포지토리를 기반으로 하며, 라이선스 검증 과정을 통해 윤리적이고 책임감 있게 구성되었다. 학습데이터에 포함된 모든 코드는 라이선스 검증 과정을 거쳐 사용되며, 저작권 문제가 없는 파일만 포함된다. 예를 들면 ScanCode[10]에서 “Permissive License” 또는 “Public Domain”으로 분류되는 라이선스로 배포되는 코드만을 포함했다.[11] 그리고 학습데이터로 사용된 소스 코드에 대해 적절한 출처를 명시하고 기여자를 인정하는 것을 목표로 한다. 아울러 데이터셋 구성 과정에서 개인 정보나 민감한 정보를 제거했다.[12] 또한, BigCode 프로젝트는 개발자들이 자신의 코드를 The Stack에서 제외할 수 있도록 "Am I in The Stack?" 도구를 제공한다.[13] 이를 통해 개발자는 자신의 코드가 데이터셋에 포함되어 있는지 확인하고, 이를 삭제 요청할 수 있다.[14]
StarCoder 및 The Stack의 의의와 한계
StarCoder와 The Stack는 오픈소스 AI의 가능성을 보여주는 대표적인 사례다. 모델의 코드는 물론, 학습에 사용된 데이터셋까지 모두 공개되어 있다. 마치 레시피의 모든 재료와 조리 과정을 투명하게 공개하는 것과 같다. 아직은 코드 생성에 특화된 모델이며, 인간처럼 다양한 분야에서 활용되기에는 한계가 있다. 하지만 StarCoder는 오픈소스 AI의 잠재력을 보여주는 중요한 이정표다. 앞으로 더욱 다양한 분야에서 오픈소스 AI 모델과 데이터셋이 개발될 것으로 기대된다. 이러한 노력은 AI 기술의 신뢰성을 높이고, 더 나아가 AI 기술 발전에 대한 사회적 참여를 확대하는 데 기여할 수 있다. 앞으로 더 많은 AI 개발자들이 StarCoder와 The Stack의 사례를 따라 투명하고 책임감 있는 AI 개발에 동참하기를 기대한다.
[1] https://opensource.org/ai/open-source-ai-definition 참조.
[2] OSAID는 학습데이터의 투명성 이외에도 코드(Code)와 모델 파라미터 및 가중치(Parameters and Weights)의 투명성도 요구하고 있다. 코드(Code)의 투명성과 관련하여, 데이터 처리 및 모델 학습에 사용된 모든 소스 코드는 OSI가 승인한 라이선스 하에 공개되어야 한다. 예를 들어, 데이터 처리 및 필터링에 사용된 코드, 사용된 인수 및 설정을 포함한 학습에 사용된 코드, 검증 및 테스트, 토크나이저와 같은 지원 라이브러리 및 하이퍼파라미터 검색 코드, 추론 코드, 모델 아키텍처를 포함해야 한다. 모델 파라미터 및 가중치(Parameters and Weights)의 투명성과 관련하여, 모델의 파라미터와 중간 학습 상태도 OSI가 승인한 조건 하에 공개되어야 하며, 이를 통해 사용자들이 모델을 수정하거나 재학습할 수 있어야 한다. 예를 들어, 여기에는 학습의 주요 중간 단계의 체크포인트와 최종 옵티마이저 상태가 포함될 수 있다.
https://opensource.org/ai/open-source-ai-definition 참조.
[3] 기초 모델(Foundation Model)은 대규모 데이터셋을 기반으로 학습된 범용 인공지능 모델로, 다양한 작업(task)에 적응할 수 있는 능력을 가진 모델을 의미한다. 이 용어는 2021년 스탠퍼드 대학의 연구자들이 처음으로 제안했다. 기초 모델은 언어, 이미지, 코드 등 여러 도메인에서 활용되며, 특정 작업에 맞게 추가 학습(미세 조정, fine-tuning)하거나 그대로 사용할 수 있다.
[4] FMTI는 Stanford, Princeton, MIT의 연구진이 개발한 평가 지표로, 기초 모델(foundation models)의 투명성을 측정하고 향상시키기 위해 설계되었다. 이 지수는 기초 모델 개발자들이 데이터, 알고리즘 설계, 그리고 모델의 활용 방식에 대해 얼마나 투명하게 정보를 공개하는지를 평가한다. 2023년 10월에 처음 발표되었으며, 이후 지속적으로 업데이트되고 있다.
https://crfm.stanford.edu/fmti/May-2024/index.html
[5] https://crfm.stanford.edu/fmti/May-2024/company-reports/index.html
[8] BigCode 프로젝트는 Hugging Face와 ServiceNow Research가 협력하여 시작한 오픈소스 기반의 코드 생성용 대규모 언어 모델(LLM) 개발 프로젝트이다. https://www.bigcode-project.org/docs/about/mission/
[11] The Stack 2.0의 구성에 관한 자세한 내용은 Lozhkov, Anton, et al. "Starcoder 2 and the stack v2: The next generation." arXiv preprint arXiv:2402.19173 (2024) 참조.
[12] https://huggingface.co/datasets/bigcode/the-stack-v2
[13] https://github.com/bigcode-project/opt-out-v2
|



